Author: Ibrahim El Kaddouri
Repository:
![]()
A Doubtfull Unstable And Useless Calculator (NUC)
This section provides a high-level overview of the NUC application. First, The custom DSL script is read and parsed. The parser generates an Abstract Syntax Tree (AST), which is structured according to the Kuifje data type. It includes various constructs such as variables, expressions, and control flow statements.
data Kuifje
= Skip
| Return Variable
| Update Statement Kuifje
| If Cond Kuifje Kuifje Kuifje
| While Cond Kuifje Kuifje
Once the script is parsed into this structured form, the evaluation phase begins.
During the evaluation phase, the Kuifje AST is traversed, and each node is evaluated based on its type. The evaluation process involves:
-
Assigning values to variables.
-
Calculating the result of expressions, such as arithmetic operations or logical conditions.
-
Handling control flow constructs like conditionals and loops.
The core idea of the application is that a computer can’t represent each
real number exactly. When assigning a value to a variable, there is a small amount of
noise added so that the possible value the variable can take becomes a distribution.
For example, assume the number 3 is not representable on a computer. Once a statement
such as X = 3 is encountered, the possible values
the computer will store instead of 3 might be 1 and 2.
The probabilities of this happening can for example be \(\frac{1}{4}\)
for 1 and 2 and a probability of \(\frac{1}{2}\) for 3.
Also, when performing arithmetic operations, it could be the case that the result is not representable on a computer due to limitations in precision. In such cases, additive noise is modelled to account for this inaccuracy. For example, consider the following Kuifje script.
y = 2;
x = 3 + y;
First, y has some disturbances because of its assignment with 2. So the distribution of y is \(\frac{1}{4}\) chance on 1, \(\frac{1}{2}\) chance on 2 and a \(\frac{1}{4}\) chance on 3. Then the possible values x can take will be \((3 + 1)\), \((3 + 2)\) or \((3 + 3)\) each with their respective probabilities. Additionally, each of those arithmetic operations will result in disturbances as well. For example, \((3 + 1)\) may result in 3, 4, or 5.
After the evaluation phase, the visualisation phase commences. The result and each variable declared in the Kuifje script is logged with their respective distribution of values.
The Kuifje DSL
The Kuifje Language resembles a very feature poor programming language. It can be written in a text file and shall be explained here below in detail.
Operators
The language supports the following keywords: if, while, return.
The language supports assignment and arithmetic operators, as well as
boolean operators:
-
Assignment Operators: Used to assign values to variables. Every assignment statement must end with a semicolon (;).
-
Arithmetic Operators: Include addition (+), subtraction (-), multiplication (*), division (/) and modulus (%).
-
Boolean Operators: Include equality (==), inequality (!=), less than or equal to (<=), less than (<), greater than or equal to (>=) and greater than (>).
Statement Structure
Every statement in the Kuifje Language follows a strict structure:
variable = expression;
Additionally, every while statement is enclosed within three brackets on
either end. This due to the fact that the outer brackets are for the
while loop. The most inner brackets are for the boolean operators such
as ( x == 3), whilst the middle brackets are to group different
boolean operators together with && and ||
while ((( conditions ))){
// code
}
Similarly, every if-else statement must adhere to the following structure:
if ((( condition ))){
// code
}
else {
// code
}
Parsing
The parser function takes a FileName as input and reads the contents
of the file with extension .kuifje. It then removes newlines from the
contents before parsing the Kuifje program. The parsing is done using
the Parsec library and if there are no syntax errors in the program,
the parsed program is returned.
Evaluation
In the evaluation phase of the program, expressions, statements, conditions and the entire program are executed, producing probabilistic outcomes. Let’s explain how each component is evaluated.
type Variable = String
type Env = Map Variable Distribution
evalExpr :: Expr -> S.State Env (Dist Int)
This function evaluates expressions in the language. It takes an expression and returns a probability distribution over integers. The use of the State monad here is significant. It allows the function to access a mapping from variables to their respective distributions. By using the State monad, variables inside expressions can be replaced by their stored distribution.
evalStatement :: Statement -> S.State Env ()
Contrastingly, the evalStatement function evaluates statements and
doesn’t return any meaningful value (). This is because a statement
results in updating a distribution of the variable on the left hand side
of the assignment.
evaluate :: Kuifje -> S.StateT Env IO (Dist Int)
The evaluate function is the core of the evaluation phase. It takes a program (Kuifje AST) and returns a probability distribution over integers. Here, a StateT transformer monad is used, combining the State monad with the ability to perform IO actions. This IO capability is crucial for generating random numbers, which are essential for introducing stochasticity into the evaluation process.
In summary, the evaluation phase leverages the State and StateT monads to manage program state and perform probabilistic computations while incorporating randomness via IO actions. This approach ensures that the IO monad doesn’t propagate throughout the entire codebase and is only needed within the evaluate function, which serves as the highest level of abstraction in the evaluation process.
Visualisation
Upon execution of the Kuifje program, we obtain two types of outcomes:
log files containing information about each variable’s probability
distribution and a Gnuplot visualization of these distributions.
Additionally, a result.log file provides summary information about the
variable declared as the result in the script file. This is the variable
associated with the return statement in the Kuifje source code.
Variable Log Files
For each variable declared in the script, a corresponding log file is generated. These log files contain detailed information about the probability distribution of the values that each variable can take. Each log file includes:
-
Total probability: The sum of probabilities across all possible values.
-
Possible values the variable can take.
-
A Histogram: A graphical representation of the distribution, showing the probability of each value.
-
Metrics:
-
Expected value of the variable
-
Variance
-
Standard deviation
-
Gnuplot Visualizations
The Gnuplot library is utilized to generate visual representations of the probability distributions for each variable. These visualizations provide a clear graphical overview of how values are distributed and their respective probabilities.
Compiling and Running
The source code is compiled using Cabal. The program can be run either directly from the source files or from the compiled executable. Below are the instructions for both methods:
Running from Source
To run the program from the source files, follow these steps:
-
Navigate to the root folder.
-
Launch the GHCi interpreter by executing the command:
ghci Src/Main.hs -
Inside GHCi, execute the
mainifunction with the path to the Kuifje program file as an argument. For example:
*Main> maini "path/to/program.kuifje"
*Main> maini "Code/program.kuifje"
Running from Executable
To run the program from the compiled executable, follow these steps:
-
Navigate to the root folder of the project containing the
Parser.cabalfile. -
Use Cabal to build and run the executable, specifying the path to the Kuifje program file using the
-fflag. For example:
cabal run CC -- -f path/to/program.kuifje
cabal run CC -- -f Code/program.kuifje
Tests
You can run the tests either via Cabal or directly in GHCi. Both methods are discussed below:
Running Tests via GHCi
To run the tests using GHCi, follow these steps:
-
Load the test module:
ghci Tests/Main.hs -
Run the main function to execute all tests:
*Main> main
Running Tests via Cabal
To run the tests using Cabal, follow these steps:
-
Navigate to the root folder of the project containing the
Parser.cabalfile. -
Run the tests using the Cabal test command:
cabal test
Test Suites Overview
The test suites include both QuickCheck and HUnit tests. QuickCheck is used for property-based testing, while HUnit is used for unit tests.
QuickCheck Tests
QuickCheck tests are used to check for invariants and properties of the functions. For example:
-
Distribution multiplication should be commutative.
-
The sum of probabilities in a distribution should be 1:
HUnit Tests
HUnit tests are used for specific, predefined cases where the expected output is known. For example:
-
Given a string representation of a Kuifje program, the parser should produce the correct AST.
-
Given two distributions, the distribution operators should result in the correct resulting distribution.
Example
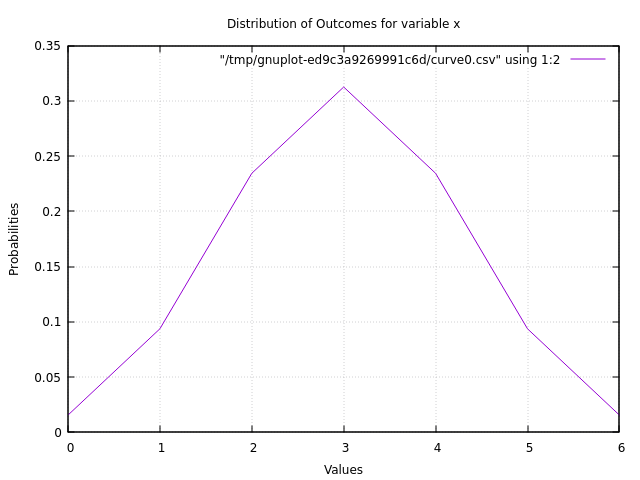
Here is an example of the results along with some plots:
Variable: x
Total Prob: 1.0
Possible values with probabilities:
[0,1,2,3,4,5,6]
Calculator Result Histogram:
0: **
1: *********
2: ***********************
3: *******************************
4: ***********************
5: *********
6: **
Metrics:
Expected value (mean): 3.0
Variance: 1.5
Standard deviation: 1.224744871391589
Discussion
While the project has reached a functional state, there are still many features that need to be addressed in order to fully implement a practical DSL.
Secondly, the use of hardcoded distributions for each operation poses limitations. A better solution could involve generating or reading distributions from external files. This would allow for greater customisation of the program.
Despite these problems, the project overall has been successful. It has provided me with insights into the usage of the State monad, which was heavily used throughout the implementation.
Additionally, the utilisation of Debug.Trace proved to be a valuable
tool, saving time during development by enabling the printing of debug
information without the need to wrap functions in an IO monad.
However, some difficulties encountered were related to the Haskell
ecosystem rather than the implementation itself. Issues such as
importing modules from different folders, executing files from
alternative directories, and correctly configuring the cabal.project
file required extra effort to resolve. Furthermore, managing
dependencies, particularly those hidden via the –lib argument.